KDD and Data Mining: KDD, an area of computer science, comprises tools and theories designed to assist humans in finding previously unexplored knowledge in large digital data collections. KDD and Data Mining may both be considered part of KDD; KDD refers specifically to discovering useful knowledge while Data Mining refers specifically to extracting patterns within data sets using algorithms; both terms can be used interchangeably.
What is KDD?
KDD stands for Knowledge Discovery in Databases. It refers to the process of extracting meaningful and useful knowledge or patterns from large volumes of data. KDD involves a series of steps and techniques aimed at uncovering hidden patterns, trends, and relationships within data sets.
The primary goal of KDD is to transform raw data into actionable knowledge that can be used for decision-making, prediction, and understanding complex phenomena. It goes beyond simple data analysis by integrating various methods from fields such as statistics, machine learning, data mining, and database systems.
The KDD process typically consists of several stages:
- Data Selection and Preprocessing: In this stage, relevant data is identified and collected from various sources. The data may undergo preprocessing steps like cleaning, integration, and transformation to ensure its quality and suitability for analysis.
- Data Mining: This stage involves the application of specific algorithms and techniques to extract patterns, relationships, and insights from the prepared data. Data mining techniques may include classification, clustering, association rule mining, regression analysis, and more.
- Interpretation and Evaluation: Once the patterns are discovered, they need to be interpreted and evaluated in the context of the problem or domain. This stage involves analyzing and understanding the significance and implications of the discovered knowledge.
- Visualization and Presentation: The final step involves presenting the discovered knowledge in a meaningful and understandable way. Visualization techniques are often used to present patterns and relationships visually, aiding in the interpretation and communication of the insights gained.
It is important to note that KDD and data mining are closely related concepts, with data mining being a specific technique employed within the broader KDD process.
What is data mining?

Data mining is a subfield of computer science and statistics that involves extracting meaningful patterns, knowledge, and insights from large datasets. It encompasses a range of techniques and algorithms designed to discover hidden relationships, trends, and patterns within data.
- The main objective of data mining is to uncover valuable information that can be used for various purposes, such as decision-making, predictive modeling, anomaly detection, and pattern recognition. By analyzing vast amounts of data, data mining enables organizations to gain a deeper understanding of their operations, customers, and markets.
Data mining techniques can be broadly categorized into several categories:
- Classification: This technique involves categorizing data into predefined classes or groups based on specific attributes or characteristics. Classification algorithms, such as decision trees, naive Bayes, and support vector machines, are commonly used for tasks like customer segmentation, email spam filtering, and credit scoring.
- Clustering: Clustering algorithms aim to identify natural groupings or clusters within the data based on similarity or proximity. It helps in discovering patterns or associations among data points without predefined classes. Clustering is useful for market segmentation, image segmentation, and anomaly detection.
- Association Rule Mining: Association rule mining focuses on identifying relationships or associations between different items in a dataset. It aims to discover patterns such as “if X, then Y” or “X implies Y.” This technique is often applied in market basket analysis, where it helps identify frequently co-occurring items, such as items typically purchased together in a retail setting.
- Regression Analysis: Regression analysis is used to predict numerical or continuous values based on the relationship between a dependent variable and one or more independent variables. It helps in understanding the impact of different factors on an outcome and enables forecasting and trend analysis.
- Neural Networks: Neural networks are computational models inspired by the human brain’s structure and functioning. They are capable of learning complex patterns and relationships from data. Neural networks are used for tasks such as image recognition, natural language processing, and predictive modeling.
- Text Mining: Text mining involves extracting useful information and knowledge from unstructured text data. Techniques such as sentiment analysis, topic modeling, and text classification are used to analyze and interpret textual data from sources like social media, customer reviews, and documents.
- Data mining plays a crucial role in various industries, including finance, healthcare, retail, telecommunications, and manufacturing. It helps organizations make data-driven decisions, enhance customer targeting, improve operational efficiency, detect fraud, and gain competitive advantages in the market.
Overall, data mining enables organizations to leverage the wealth of information available in their datasets and turn it into valuable insights that drive business success.
Understanding KDD
Understanding Knowledge Discovery in Databases (KDD) involves grasping the process, goals, and significance of this approach to extracting knowledge from large datasets. KDD is an interdisciplinary field that combines techniques from statistics, machine learning, data mining, and database systems to uncover hidden patterns and insights within data.
Let’s explore the key aspects of understanding KDD:
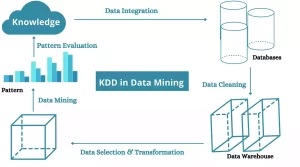
Process: KDD encompasses a series of steps to transform raw data into meaningful knowledge:
a. Data Selection and Preprocessing: Relevant data is collected and prepared for analysis, including tasks like data cleaning, integration, and transformation.
b. Data Mining: Various data mining techniques and algorithms are applied to extract patterns, relationships, and insights from the prepared data.
c. Interpretation and Evaluation: The discovered patterns are interpreted, evaluated, and assessed for their significance and relevance.
d. Visualization and Presentation: The results are visualized and presented in a clear and understandable manner to facilitate decision-making.
Goals: The primary objective of KDD is to derive actionable knowledge from data. This knowledge can be used for decision-making, prediction, understanding complex phenomena, and gaining insights into business processes or scientific domains.
- Iterative and Interactive Nature: KDD is an iterative process, where the steps mentioned above are often revisited and refined. Domain experts play a vital role in guiding the process, providing context, and validating the findings. Human expertise and domain knowledge are crucial in formulating hypotheses and exploring data effectively.
- Scope: KDD represents a broader framework that encompasses various stages, including data preprocessing, data mining, and result interpretation. Data mining is a specific technique within the KDD process, focusing on uncovering patterns and relationships.
- Data Sources: KDD can leverage diverse data sources, including structured databases, text documents, sensor data, social media feeds, and more. The availability of big data and advancements in computing power have significantly expanded the possibilities and potential impact of KDD.
- Practical Applications: KDD finds applications across numerous fields and industries. It is used in finance for fraud detection and risk assessment, in healthcare for patient monitoring and disease prediction, in marketing for customer segmentation and campaign optimization, and in scientific research for data exploration and hypothesis generation.
- Ethical Considerations: As KDD deals with large amounts of data, it is important to address ethical concerns related to privacy, data protection, and potential biases in the analysis. Ensuring responsible data usage and adhering to legal and ethical guidelines is crucial in KDD projects.
Understanding KDD provides organizations with the means to unlock valuable insights, make informed decisions, and gain a competitive edge in today’s data-driven world. By harnessing the power of data and applying the iterative KDD process, organizations can transform raw data into actionable knowledge, fostering innovation and success.
Unraveling Data Mining
Unraveling data mining involves delving into the intricacies of this technique, its objectives, common algorithms, and its applications across various domains. Let’s explore the key aspects of understanding data mining:
Definition: Data mining is the process of extracting hidden patterns, knowledge, and insights from large datasets. It involves applying statistical and machine learning techniques to discover relationships, trends, and anomalies in the data that may not be readily apparent.
Objectives: The primary goals of data mining include:
a. Pattern Extraction: Data mining aims to identify meaningful patterns, correlations, and associations within the data. These patterns can provide valuable insights into customer behavior, market trends, and other phenomena of interest.
b. Predictive Modeling: Data mining techniques can be used to build predictive models that make accurate predictions or forecasts based on historical data.
c. Anomaly Detection: Data mining helps in detecting unusual or anomalous patterns or behaviors that deviate significantly from the norm, aiding in fraud detection, intrusion detection, and quality control.
Common Algorithms: Data mining employs various algorithms and techniques, including:
a. Classification: Algorithms like decision trees, logistic regression, and support vector machines are used to classify data into predefined categories or classes.
b. Clustering: Clustering algorithms group similar data points together based on their characteristics or proximity, helping in finding natural groupings within the data.
c. Association Rules: Association rule mining discovers relationships and co-occurrences between different items or variables, enabling insights such as “people who buy X also tend to buy Y.”
d. Neural Networks: Neural networks are computational models inspired by the human brain, capable of learning complex patterns and relationships from data.
e. Regression Analysis: Regression algorithms help in predicting numerical values based on the relationships between variables.
Applications:
Data mining has a wide range of applications in various fields:
a. Business and Marketing: Data mining aids in customer segmentation, market basket analysis, churn prediction, and targeted advertising.
b. Healthcare: It helps in disease prediction, patient monitoring, and identifying risk factors.
c. Finance: Data mining is used for credit scoring, fraud detection, and stock market analysis.
d. Manufacturing: It assists in quality control, supply chain optimization, and predictive maintenance.
e. Research and Science: Data mining helps in exploring large datasets, identifying scientific patterns, and hypothesis generation.
Data Preparation: Data mining requires appropriate data preparation, including cleaning, integration, transformation, and feature selection, to ensure high-quality and relevant input for the algorithms.
Evaluation and Validation: It is essential to evaluate the results of data mining models to ensure their reliability and generalizability. Techniques such as cross-validation, holdout testing, and performance metrics are used for model assessment.
Unraveling data mining allows organizations to extract valuable insights from their data, make data-driven decisions, and gain a competitive advantage. By applying sophisticated algorithms and techniques, data mining uncovers hidden patterns, predicts future trends, and supports evidence-based decision-making across diverse industries and domains.
Key Differences Between KDD and Data Mining
Understanding the key differences between KDD (Knowledge Discovery in Databases) and data mining helps clarify their individual scopes, methodologies, and objectives. While they are related concepts, they have distinct characteristics.
Let’s explore the key differences between KDD and data mining:
Scope and Purpose:
KDD: KDD is a comprehensive framework that encompasses the entire process of discovering knowledge from data. It includes stages like data selection, preprocessing, data mining, and result interpretation. KDD aims to transform raw data into actionable knowledge for decision-making and insight generation.
Data Mining: Data mining, on the other hand, is a specific technique or subset within the broader KDD process. It focuses primarily on applying algorithms and methods to extract patterns, relationships, and insights from data.
Methodology and Process:
KDD: KDD involves an iterative and interactive process. It emphasizes the importance of human expertise and domain knowledge in guiding the exploration, hypothesis generation, and interpretation of results. It encompasses steps like data selection, preprocessing, data mining, and result evaluation, involving both automated algorithms and human-guided analysis.
Data Mining: Data mining is more algorithm-centric and automated. It primarily focuses on the application of algorithms and techniques to extract patterns and relationships from data. It may not involve the same level of human intervention and exploration as seen in KDD.
Emphasis on Domain Expertise:
KDD: KDD places significant importance on domain expertise and the involvement of domain experts throughout the process. Domain experts contribute their knowledge, understanding, and insights to guide the selection of relevant data, interpret the results, and provide context to the discovered knowledge.
Data Mining: While data mining may benefit from domain expertise, it does not emphasize it to the same extent as KDD. Data mining techniques often operate in a more automated and algorithm-driven manner, with less direct involvement of domain experts in the analysis process.
Goals and Outputs:
KDD: The goal of KDD is to extract actionable knowledge and insights from data. It focuses on generating knowledge that can be applied to real-world problems, facilitating decision-making and understanding complex phenomena. The outputs of KDD are typically comprehensive reports, visualizations, and actionable recommendations.
Data Mining: Data mining primarily aims to extract patterns, relationships, and insights from data. Its focus is on identifying valuable information that can be used for prediction, classification, clustering, or association discovery. The outputs of data mining are typically patterns, models, or predictions derived from the data.
While KDD and data mining are interconnected, the key differences lie in the scope, methodology, emphasis on domain expertise, and the goals they pursue. KDD provides a holistic framework for knowledge discovery from data, incorporating various stages and human expertise, whereas data mining specifically focuses on algorithmic techniques to extract patterns and relationships. Both approaches contribute to leveraging data for valuable insights, but they have distinct characteristics within the broader field of data analysis and knowledge discovery.
Practical Applications and Use Cases
Both KDD (Knowledge Discovery in Databases) and data mining have a wide range of practical applications and use cases across various industries. Let’s explore some of the common applications where these approaches are employed:
- Business and Marketing
Customer Segmentation: KDD and data mining techniques help businesses identify distinct customer segments based on their behaviors, preferences, and demographics. This information enables targeted marketing campaigns and personalized customer experiences.
Market Basket Analysis: By analyzing transaction data, associations and relationships between products or services can be discovered. This information aids in cross-selling, product placement, and promotional strategies.
Churn Prediction: KDD and data mining techniques can be utilized to predict customer churn, allowing companies to take proactive measures to retain valuable customers.
Sales Forecasting: By analyzing historical sales data and external factors, data mining techniques can be used to forecast future sales, supporting inventory management and resource planning.
Healthcare: KDD and data mining techniques can assist in predicting disease outcomes, identifying risk factors, and supporting early diagnosis based on patient data and medical records.
Clinical Decision Support: By analyzing patient data, treatment outcomes, and medical research, data mining techniques can provide decision support systems to aid healthcare professionals in making informed treatment decisions.
Patient Monitoring and Fraud Detection: KDD and data mining techniques can be applied to monitor patient vital signs, detect anomalies, and identify potential fraudulent activities in healthcare claims.
- Finance and Banking
Credit Scoring: Data mining techniques enable the analysis of customer credit history, financial behavior, and other relevant factors to assess creditworthiness and determine appropriate credit scores.
Fraud Detection: KDD and data mining techniques help detect fraudulent activities such as credit card fraud, identity theft, and money laundering by analyzing transaction patterns and identifying unusual behaviors.
Risk Assessment: Data mining can assist in assessing and managing financial risks by analyzing historical data, market trends, and external factors to predict and mitigate potential risks.
- Manufacturing and Operations
Quality Control: KDD and data mining techniques can be utilized to monitor and analyze manufacturing processes, identify patterns of defects or quality issues, and implement preventive measures.
Supply Chain Optimization: Data mining techniques can analyze supply chain data to identify bottlenecks, optimize inventory levels, and improve overall efficiency.
Predictive Maintenance: By analyzing sensor data and historical maintenance records, data mining techniques can predict equipment failures or maintenance needs, allowing proactive maintenance planning and minimizing downtime.
- Scientific Research
Genomics and Proteomics: KDD and data mining techniques are used in genomics and proteomics research to analyze large-scale biological datasets, identify genetic markers, and understand complex biological interactions.
Climate Modeling: Data mining techniques help analyze climate data, identify patterns, and predict future climate conditions, supporting climate modeling and environmental research.
Drug Discovery: Data mining techniques aid in analyzing molecular data, identifying potential drug candidates, and predicting drug properties for pharmaceutical research.
These are just a few examples of the practical applications and use cases of KDD and data mining. The versatility of these approaches allows their application across diverse domains, helping organizations extract valuable insights, make informed decisions, and drive innovation.
Conclusion
KDD (Knowledge Discoveries in Databases) as well as data mining, are two related however they are distinct processes within the area that deals with data analysis. KDD is the procedure of obtaining valuable knowledge from massive datasets, which includes data preprocessing, selection transform, mining and evaluation. Data mining is on the other hand specifically, refers to the use of algorithms in order to identify patterns connections, patterns, and other information within the data. In the event that KDD is a complete method and approach, data mining is a vital part of this process. It allows businesses to find valuable data and make informed decisions.